Mysql数据库入门
MySQL的SQL语句:
SQL:结构化查询语言
DDL:数据定义语言:定义数据库,数据表的结构:create,drop,alter
DML:数据操纵语言:主要是用来操纵数据 insert,update,delete
DCL:数据控制语言:定义访问权限,取消访问权限,安全设置 grant
DQL:数据查询语言:select, from子句 where子句
delete和truncate的区别:
delete:DML:一条一条地删除表中数据:适用于数据量比较少的表
truncate:DDL:先删除表,再重建表:适用于数据量比较多的表
数据库:


总结:
一。 数据库操作
数据库的创建 : create database 数据库的名 character set 字符集 collate 校对规则
数据库的删除: drop database 数据库名
修改: alter database 数据库 character set 字符集(utf8)
查询: show databases;
show create database 数据库的名字
select database();
切换数据库 : use 数据库的名字
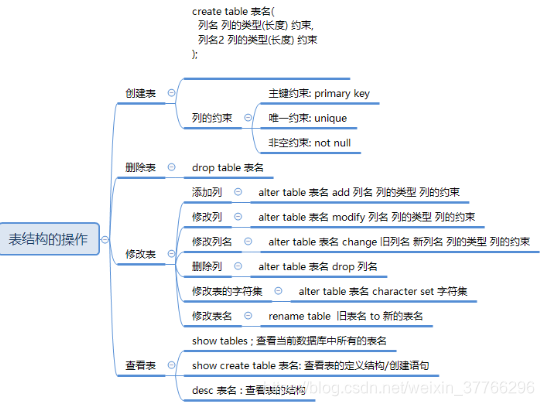
二。表结构操作:
创建: create table 表名(
列名 列的类型 列的约束,
列名 列的类型 列的约
)
列的类型: char / varchar
列的约束:
primary key 主键约束
unique : 唯一约束
not null 非空约束
自动增长 : auto_increment
删除 : drop table 表名
修改: alter table 表名 (add, modify, change , drop)
rename table 旧表名 to 新表名
alter table 表名 character set 字符集
查询表结构:
show tables; 查询出所有的表
show create table 表名: 表的创建语句, 表的定义
desc 表名: 表的结构
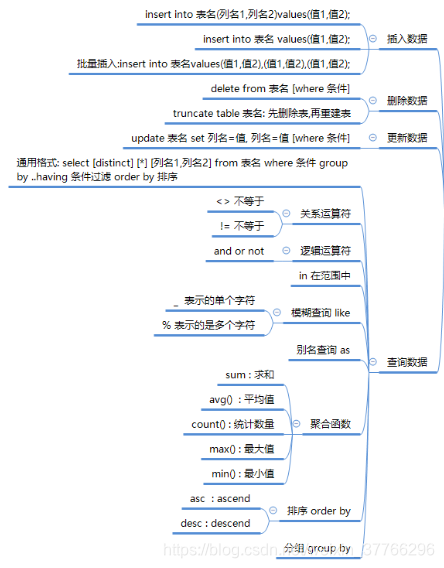
三。 表中数据操作:
插入: insert into 表名(列名,列名) values(值1,值2);
删除: delete from 表名 [where 条件]
修改: update 表名 set 列名=‘值’ ,列名=‘值’ [where 条件];
查询: select [distinct] * [列名1,列名2] from 表名 [where 条件]
as关键字: 别名
where条件后面:
关系运算符: > >= < <= != <>
--判断某一列是否为空: is null is not null
in 在某范围内
between…and
逻辑运算符: and or not
模糊查询: like
_ : 代表单个字符
%: 代表的是多个字符
分组: group by
分组之后条件过滤: having
聚合函数: sum() ,avg() , count() ,max(), min()
排序: order by (asc 升序, desc 降序)
having关键字和where关键字的区别:
having关键字:可以接聚合函数,出现分组之后
where关键字:不可以接聚合函数,出现在分组之前
编写顺序:select 。。from。。where。。group by。。having。。order by。。
执行顺序:from。。 where。。group by 。。having。。select。。order by。。
数据库操作练习:

三、数据表的结构的修改:
四、查看表结构
1、查看数据库内的所有表
SHOW TABLES;
2、查看employee的建表语句
SHOW CREATE TABLE employee;
3、查看employee的表结构
DESC employee;
表记录操作:
二、更新语句 —UPDATE
1、将所有员工薪水修改为5000元。
UPDATE employee SET salary=5000;
UPDATE employee SET salary=5000 WHERE NAME=‘wangwu’;
2、将姓名为’zs’的员工薪水修改为3000元。
UPDATE employee SET salary=3000 WHERE NAME=‘zs’;
3、将姓名为’ls’的员工薪水修改为4000元,job改为ccc。
UPDATE employee SET salary=4000,job=‘ccc’ WHERE NAME=‘ls’;
4、将wangwu的薪水在原有基础上增加1000元。
UPDATE employee SET salary=salary+1000 WHERE NAME=‘wangwu’;
三、删除语句 —DELETE
1、删除表中名称为’zs’的记录。
DELETE FROM employee WHERE NAME=‘zs’;
2、删除表中所有记录。
DELETE FROM employee;
四、查询语句 —SELECT
CREATE TABLE exam(
id INT PRIMARY KEY AUTO_INCREMENT,
NAME VARCHAR(20) NOT NULL,
chinese DOUBLE,
math DOUBLE,
english DOUBLE
);
INSERT INTO exam VALUES(NULL,‘关羽’,85,76,70);
INSERT INTO exam VALUES(NULL,‘张飞’,70,75,70);
INSERT INTO exam VALUES(NULL,‘赵云’,90,65,95);
INSERT INTO exam VALUES(NULL,‘刘备’,97,50,50);
INSERT INTO exam VALUES(NULL,‘曹操’,90,89,80);
INSERT INTO exam VALUES(NULL,‘司马懿’,90,67,65);
练习:
多表之间关系的维护:
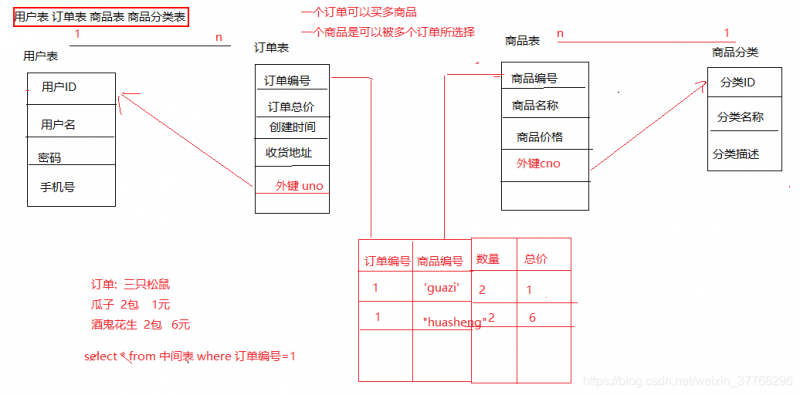
以商品表和分类表为例(一对多的关系):
外键约束:
- 多表之间的关系如何维护: 外键约束 : foreign key
- 添加一个外键: alter table product add foreign key(cno) references category(cid);
- foreign key(cno) references category(cid)
- 删除的时候, 先删除外键关联的所有数据,再才能删除分类的数据
- 建表原则:
- 一对多:商品和类别
- 建表原则: 在多的一方增加一个外键,指向一的一方
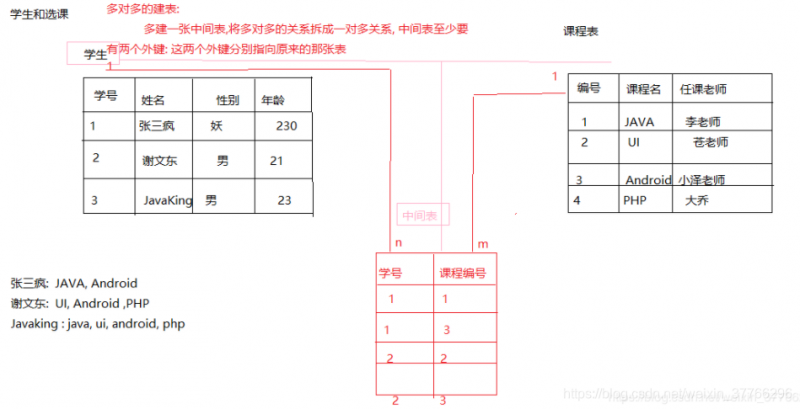
**- 多对多:**老师和学生, 学生和课程
- 建表原则: 将多对多转成一对多的关系,创建一张中间表
- 
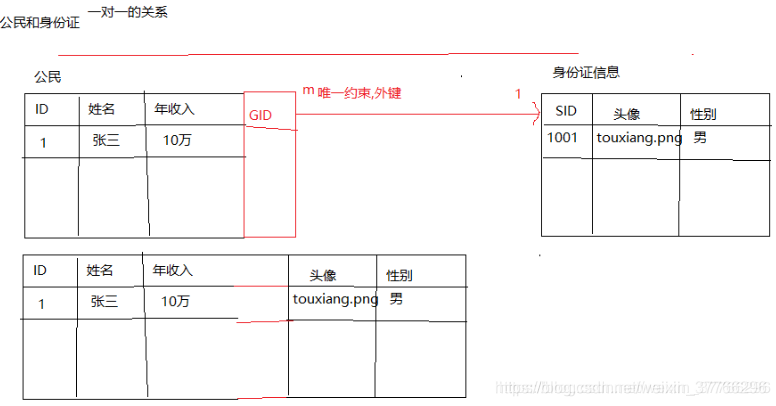
- 一对一: 不常用, 拆表操作:班级和班长, 公民和身份证, 国家和国旗
- 建表原则: 将两张表合并成一张表
- 将两张表的主键建立起关系
- 将一对一的关系当作一对多的关系去处理
- 相亲网站:
- 个人信息 : 姓名,性别,年龄,身高,体重,三围,兴趣爱好,(年收入, 特长,学历, 职业, 择偶目标,要求)
- 拆表操作 : 将个人的常用信息和不常用信息,避免表的臃肿
- 
以商城为例来分析:
先分析表与表之间的关系:



主键约束和唯一约束:
主键约束: 默认就是不能为空, 唯一
- 外键都是指向另外一张表的主键
- 主键一张表只能有一个
唯一约束: 列面的内容, 必须是唯一, 不能出现重复情况, 不可为空
- 唯一约束不可以作为其它表的外键
- 可以有多个唯一约束
内连接,做连接,右连接:
- 交叉连接查询 笛卡尔积
SELECT * FROM product;
SELECT * FROM category;
笛卡尔积 ,查出来是两张表的乘积 ,查出来的结果没有意义
SELECT * FROM product,category;
–过滤出有意义的数据
SELECT * FROM product,category WHERE cno=cid;
SELECT * FROM product AS p,category AS c WHERE p.cno=c.cid;
SELECT * FROM product p,category c WHERE p.cno=c.cid;
–数据准备
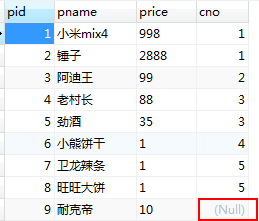
INSERT INTO product VALUES(NULL,‘耐克帝’,10,NULL);
- 内连接查询
– 隐式内链接
SELECT * FROM product p,category c WHERE p.cno=c.cid;
– 显示内链接
SELECT * FROM product p INNER JOIN category c ON p.cno=c.cid;
– 区别:
隐式内链接: 在查询出结果的基础上去做的WHERE条件过滤
显示内链接: 带着条件去查询结果, 执行效率要高
product表:
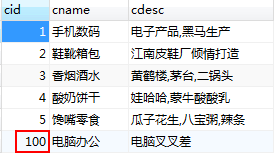
category表:
-
内连接:普通逻辑进行运算
-
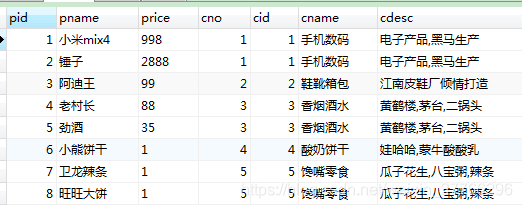
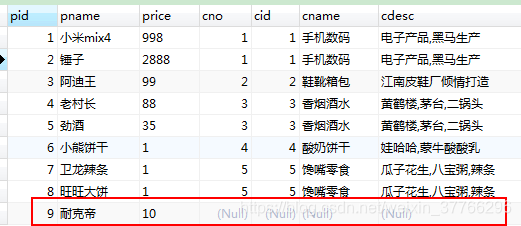
左外连接,会将左表中的所有数据都查询出来, 如果右表中没有对应的数据,用NULL代替
SELECT * FROM product p LEFT OUTER JOIN category c ON p.cno=c.cid;
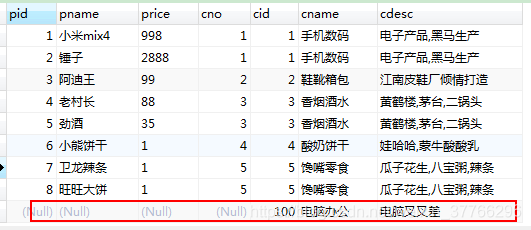
- 右外连接: 会将右表所有数据都查询出来, 如果左表没有对应数据的话, 用NULL代替
SELECT * FROM product p RIGHT OUTER JOIN category c ON p.cno=c.cid;
分页查询
-
每页数据数据3
-
起始索引startIndex: index 代表显示第几页 页数从1开始,起始索引从0开始
-
第1页: 0
-
第2页: 3
select * from product limit 0,3;
select * from product limit 3,3;每页显示3条数据(3为pageSize)
startIndex = (index-1)*pageSize
第一个参数是索引
第二个参数显示的个数
select * from product limit startIndex,pageSize;
子查询:
– 查询 分类名称为手机数码的所有商品
1.查询分类名为手机数码的ID
SELECT cid FROM category WHERE cname=‘手机数码’;
2.得出ID为1的结果
SELECT * FROM product WHERE cno = (SELECT cid FROM category WHERE cname=‘手机数码’);
– 查询出(商品名称,商品分类名称)信息
–左连接
SELECT p.pname,c.cname FROM product p LEFT OUTER JOIN category c ON p.cno = c.cid;
–子查询
SELECT pname ,(SELECT cname FROM category c WHERE p.cno=c.cid ) AS 商品分类名称 FROM product p;
– 单行子查询(> < >= <= = <>)
– 查询出高于10号部门的平均工资的员工信息
1.10号部门的平均工资
SELECT AVG(sal) FROM emp WHERE deptno = 10;
2. 高于上面结果员工信息
SELECT * FROM emp WHERE sal > (SELECT AVG(sal) FROM emp WHERE deptno = 10);
– 多行子查询(in not in any all) >any >all
– 查询出比10号部门任何员工薪资高的员工信息
1. 查询出10号部门最高工资
SELECT MAX(sal) FROM emp WHERE deptno = 10;
2. 得出结果
SELECT * FROM emp WHERE sal > (SELECT MAX(sal) FROM emp WHERE deptno = 10);
– 查询出比10号部门任意一个员工薪资高的所有员工信息 : 只要比其中随便一个工资都可以
SELECT sal FROM emp WHERE deptno = 10;
– 多列子查询(实际使用较少) in
– 和10号部门同名同工作的员工信息
1. 查询出10号部门所有人 名字和工作
SELECT ename,job FROM emp WHERE deptno=10;
2. 得出结果
SELECT * FROM emp WHERE (ename,job) IN (SELECT ename,job FROM emp WHERE deptno=10) AND deptno !=10;
– Select后面接子查询
– 获取员工的名字和部门的名字
SELECT ename,deptno FROM emp ;
– from后面接子查询
– 查询emp表中所有管理层的信息
SELECT DISTINCT mgr FROM emp;
– where 接子查询
– 薪资高于10号部门平均工资的所有员工信息
1. 10号部门平均工资
SELECT AVG(sal) FROM emp WHERE deptno=10;
2. 得出结果
SELECT * FROM emp WHERE sal > (SELECT AVG(sal) FROM emp WHERE deptno=10);
– having后面接子查询
– 有哪些部门的平均工资高于30号部门的平均工资
1. 统计所有的部门的平均工资
SELECT deptno, AVG(sal) FROM emp GROUP BY deptno;
2. 30号部门的平均工资
SELECT AVG(sal) FROM emp WHERE deptno=30;
3.得出结果:
SELECT deptno, AVG(sal) FROM emp GROUP BY deptno HAVING AVG(sal) > (SELECT AVG(sal) FROM emp WHERE deptno=30);
– 列出达拉斯加工作的人中,比纽约平均工资高的人
-
查处达拉斯加工作的人
- 查询出达拉斯的部门编号
SELECT deptno FROM dept WHERE loc =‘DALLAS’; - SELECT * FROM emp WHERE deptno = ( SELECT deptno FROM dept WHERE loc =‘DALLAS’);
- 查询出达拉斯的部门编号
-
查出纽约工作的人的平均工资
- 查处纽约的部门编号
SELECT deptno FROM dept WHERE loc =‘NEW YORK’; - SELECT AVG(sal) FROM emp WHERE deptno = (SELECT deptno FROM dept WHERE loc =‘NEW YORK’);
- 查处纽约的部门编号